In diesem Beitrag habe ich erkärt, wieso weshalb warum ich die Scripte zum KAVA autocompouding gebaut habe.
Mit dem KAVA-10 Mainnet update musste ich meine scripts anpassen, hier die aktuellen Versionen:
In diesem Beitrag habe ich erkärt, wieso weshalb warum ich die Scripte zum KAVA autocompouding gebaut habe.
Mit dem KAVA-10 Mainnet update musste ich meine scripts anpassen, hier die aktuellen Versionen:
kava.io bietet DeFI auf der BEP2 Chain an. KAVA Tokens können gestaked werden, aktuell gibt es um die 20% APR. Mit Wallets wie z.B. dem Trustwallet oder Ledger kann man KAVA staken. Möchte man jedoch vom Zinsenzinseffekt profitieren, so muss man derzeit manuell seine Staking-Rewards einsammeln und manuell wieder erneut delegieren.
Aber es handelt sich ja um eine Kryptowährung, welche sich bekanntlich programmieren lassen. Daher habe ich schnell mal das SDK gezogen, etwas gepatcht und folgenden Autocompounder gebaut:
autocompounder.js:
const Env = require("./env").env;
const kavaUtils = require("./src/utils").utils;
'use strict';
const KavaClient = require('./src/client').KavaClient;
const tx = require('./src/tx').tx;
const msg = require('./src/msg').msg;
const utils = require('./src/utils').utils;
const crypto = require('./src/crypto').crypto;
module.exports = {
KavaClient,
tx,
msg,
utils,
crypto,
};
const KAVA_CONVERSION_FACTOR = 10 ** 6;
const COMPOUND_LIMIT = 0.2 ; // the amount of pending rewards at which we start autocompounding
var main = async () => {
kavaClient = new KavaClient(Env.KavaEndpoints.Mainnet);
kavaClient.setWallet(Env.KavaAccount.Mainnet.Mnemonic);
kavaClient.setBroadcastMode("async");
await kavaClient.initChain();
unused_balance = 0;
console.log("Account:", Env.KavaAccount.Mainnet.Address);
let balances = await kavaClient.getBalances(Env.KavaAccount.Mainnet.Address);
let kavaBalance = balances.find((item) => item.denom.toUpperCase() === "UKAVA");
if(kavaBalance) {
console.log("\tBalance (kava):", kavaBalance.amount / KAVA_CONVERSION_FACTOR);
unused_balance = kavaBalance.amount / KAVA_CONVERSION_FACTOR ;
}
let kavaDelegations = await kavaClient.getDelegations(Env.KavaAccount.Mainnet.Address);
let staked = 0 ;
let validators = [];
let bal_before = 0;
for (let element of kavaDelegations) {
let balance = element.balance;
validators.push(element.validator_address);
staked = staked + (balance.amount / KAVA_CONVERSION_FACTOR);
if (bal_before < staked ) {
bal_before = staked;
next_val = element.validator_address;
}
}
console.log("\tStaked (kava):" , staked) ;
console.log("\tnext validator: ", next_val);
if (unused_balance > COMPOUND_LIMIT) {
let new_stake_balance = unused_balance - 0.01 ;
console.log("new staking: ", new_stake_balance);
denom_val = new_stake_balance.toFixed(5) * KAVA_CONVERSION_FACTOR;
let txMsgs = [] ;
txMsgs.push ( {
type: 'cosmos-sdk/MsgDelegate',
value: {
delegator_address: Env.KavaAccount.Mainnet.Address,
validator_address: next_val,
amount: {denom:'ukava', amount: denom_val.toString() }
},
});
let txid = await kavaClient.sendTx(txMsgs, fee={amount: [{ denom: 'ukava', amount: "0" }], gas: String(300000)}, null);
console.log("stake kava, created TX ", txid) ;
}
let kavaRewards = await kavaClient.getDistributionRewards(Env.KavaAccount.Mainnet.Address);
let Rewards = kavaRewards.total.find((item) => item.denom.toUpperCase() === "UKAVA");
if(Rewards) {
console.log("\tStaking Rewards (kava):", Rewards.amount / KAVA_CONVERSION_FACTOR);
}
if (Rewards.amount / KAVA_CONVERSION_FACTOR > COMPOUND_LIMIT) {
console.log("time to get rewards!");
let txMsgs = [] ;
for (let val of validators) {
txMsgs.push ( {
type: 'cosmos-sdk/MsgWithdrawDelegationReward',
value: {
delegator_address: Env.KavaAccount.Mainnet.Address,
validator_address: val,
},
});
}
let txid = await kavaClient.sendTx(txMsgs, fee={amount: [{ denom: 'ukava', amount: "0" }], gas: String(300000)}, null);
console.log("fetched rewards, created TX ", txid) ;
}
}
main();
env.js:
const KavaAccount = {
Local: {
Address: "",
Mnemonic: ""
},
Testnet: {
Address: "",
Mnemonic: "",
},
Mainnet: {
Address: "kava1757uf8nmejhlqnmk99n4d9y78taud4neneutus",
Mnemonic: "send some kava to my address to show some love",
}
}
const KavaEndpoints = {
Local: "http://localhost:1317",
Testnet: "https://kava-testnet-8000.kava.io",
Mainnet: "https://api.kava.io",
}
const KavaDeputy = {
Testnet: "kava1tfvn5t8qwngqd2q427za2mel48pcus3z9u73fl",
Mainnet: "kava1r4v2zdhdalfj2ydazallqvrus9fkphmglhn6u6",
}
const BinanceAccount = {
Testnet: {
Address: "",
Mnemonic: "",
},
Mainnet: {
Address: "",
Mnemonic: ""
}
}
const BinanceEndpoints = {
Testnet: "https://testnet-dex.binance.org",
Mainnet: "https://dex.binance.org/",
}
const BinanceDeputy = {
Testnet: "tbnb1et8vmd0dgvswjnyaf73ez8ye0jehc8a7t7fljv",
Mainnet: "bnb1jh7uv2rm6339yue8k4mj9406k3509kr4wt5nxn"
}
module.exports.env = {
KavaAccount,
KavaEndpoints,
KavaDeputy,
BinanceAccount,
BinanceEndpoints,
BinanceDeputy
}
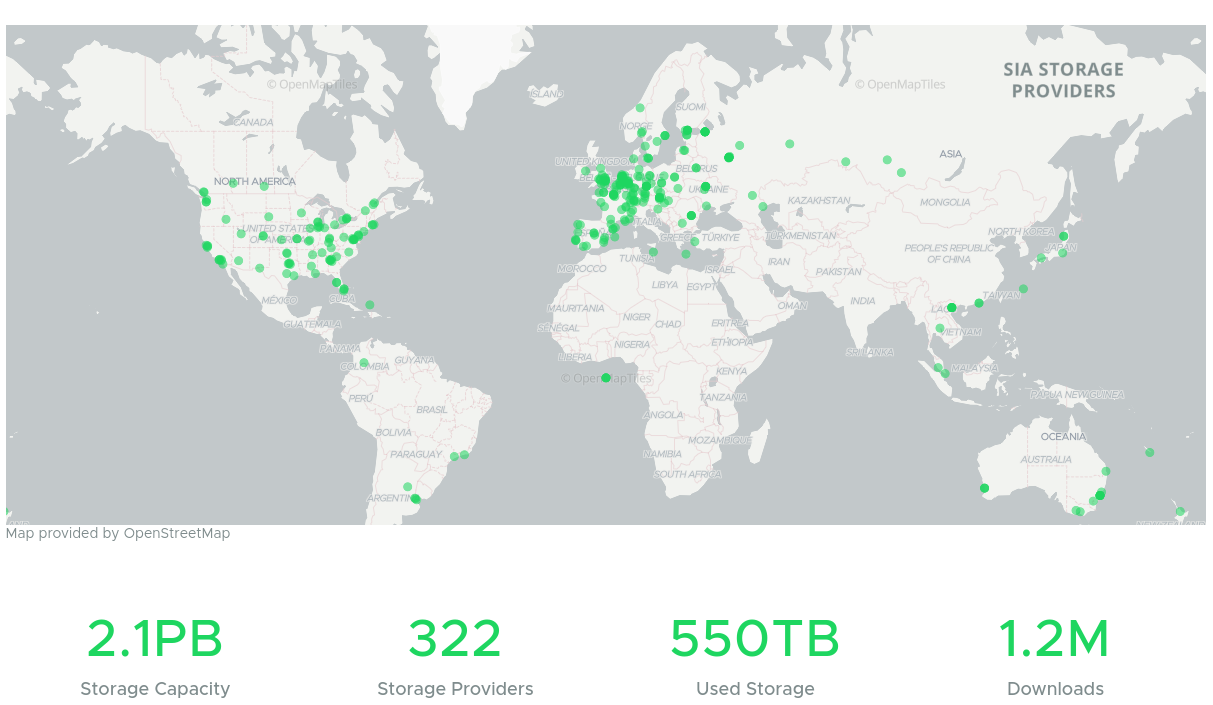
Google Drive, Amazon S3, Dropbox, Icloud – viele kennen diese Cloudservices und nutzen sie. Meistens geht alles gut, aber folgendes sollte einem doch zu denken geben:
“Dropbox ist dazu übergegangen, die Konten von Nutzern zu sperren, die gegen das Urheberrecht verstoßen bzw. deren Konten mehrfach Gegenstand von Anschuldigungen wegen Urheberrechtsverstößen waren.”
D.h. unter gewissen Umständen kommt man nicht mehr an seine Daten. Man ist den Anbietern sozusagen ausgeliefert. Abhilfe schaffen hier blockchainbasierte Services, welche Daten verteilt redundant und verschlüsselt auf vielen verschiedenen Rechnern im Netz speichern. Unter https://sia.tech bekommt man ein hübsches GUI für das Sia storage Netzwerk. Die Idee ist einfach: Das Netzwerk wird über eine Blockchain durch Mining abgesichert und Verträge werden darüber geschlossen. User, die Speicherplatz zur Verfügung stellen erhalten eine Vergütung, andere User können den Speicher mieten. Durch sia ist sichergestellt dass die Daten mehrfach im Netzwerk gespeichert werden und dass diese verschlüsselt abgelegt sind. Nur der Nutzer mit den entsprechenden wallet erhält Zugriff auf seine Dateien.
Das Userinterface Sia UI ist für Endanwender gemacht. Es läuft unter Windows, macOS und Linux. Es gibt auch die Möglichkeit, Sia über NDB zu mounten, was ich jedoch nicht zuverlässig betreiben konnte. (sia-nbdserver) oder mittels FUSE zu mounten, allerdings bisher nur read-only. Eine weitere Möglichkeit bietet die Sia API. Einige kennen vielleicht schon Nextcloud, den Owncloud Nachfolger und haben diesen schon genutzt. Bei diesem kann man auch externe Speicher einbinden, wie z.B. Google Drive oder Dropbox, man hat dann aber eben das Problem nicht Herr seiner Daten zu sein. Vor ein paar Jahren gab es schon mal ein externes Storage Modul für Nextcloud zur Einbindung von Sia Storage, allerdings hat man es nun 3 Jahre lang nicht weiterentwickelt. Mit der aktuellen Nextcloud 20 lief es nicht.
Aus diesem Grund habe ich mir den Code einmal angeschaut und für Nextcloud 20 flottgemacht. Ein paar Features, die ich im Gitlab zu dem Projekt gefunden habe, konnte ich direkt mit umsetzen. Die aktuelle Version gibt es hier: https://gitlab.com/f.wiessner/Sia-Nextcloud
Hier noch kurz ein kleines “Howto”, wie man das ganze in Betrieb nimmt. Vorraussetzung sind ein installiertes Nextcloud 20, ein installiertes sia (man kann hier einfach das neue siastream nutzen, welches gleich Contracts etc erstellt und nutzerfreundlicher ist) und den Code von meinem Repository.
Siastream gibt es unter https://siastream.tech/, aktuell in Version 1.0.4. Sobald man es heruntergeladen, entpackt und gestartet hat, braucht man sich um nichts weiter kümmern. Siastream installiert den Sia-Daemon gleich mit und startet auch den Sync der Sia-Chain automatisch. Unter http://localhost:3000 bzw. wenn man siastream mit –host 0.0.0.0 startet unter der IP des Servers Port 3000 kommt man auf das Administrationsinterface.
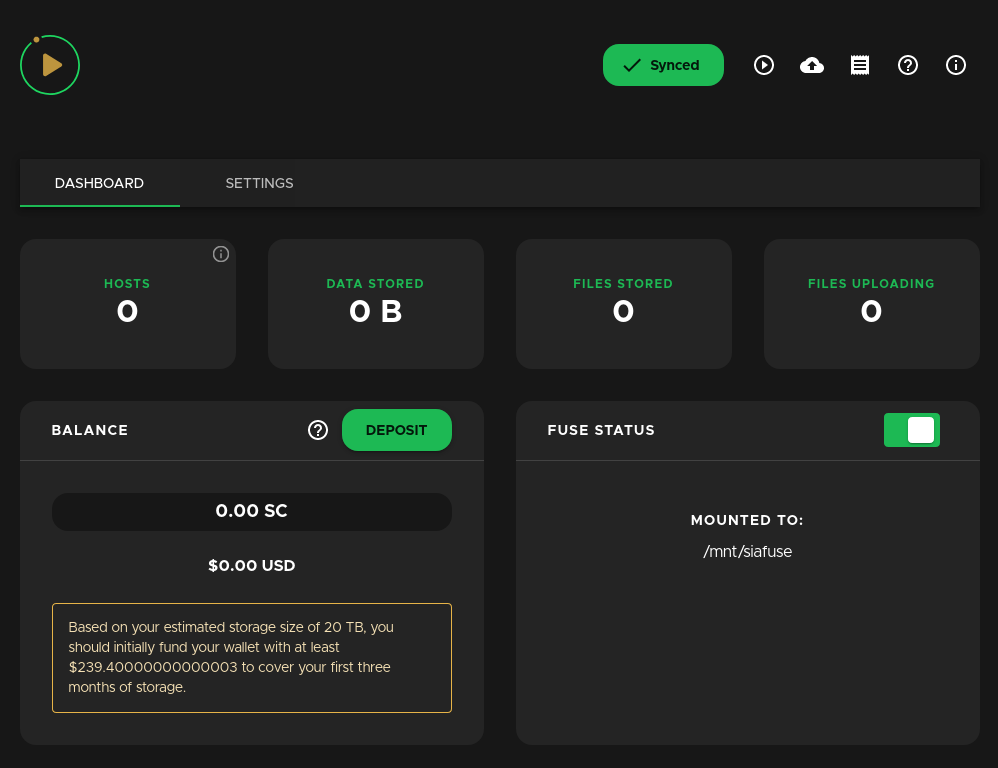
Unter Deposit kann man dann Siacoins hinterlegen die man benötigt um Contracts zu schliessen. Aktuell kostet 1 TB ca. 5 US $ pro Monat. Sia Coins (Kürzel SC) gibt es z.B. bei Binance (https://www.binance.com/en/register?ref=KM4WQJ9K) – mit meinem Link bekommst Du 5% Rabatt auf Transaktionsgebühren jeglicher Art! Nachdem man eine Menge an SC aufgeladen hat, kann es dann auch schon losgehen:
Den Code von meinem Repository hier herunterladen: https://gitlab.com/f.wiessner/Sia-Nextcloud z.B. mit
git clone https://gitlab.com/f.wiessner/Sia-Nextcloud.gitDen Code kopiert man in die Nextcloud Installation in den Ordner nextcloud/apps/files_external_sia
mkdir nextcloud/apps/files_external_sia ; cp -dpr Sia-Nextcloud/* nextcloud/apps/files_external_siaUnter Umständen muss in nextcloud/apps/files_external_sia/sia-php/Requests noch https://github.com/WordPress/Requests/ nachgeladen werden:
cd apps/files_external_sia/sia-php/ ; git clone https://github.com/WordPress/Requests.gitNun kann man unter Settings im External Storage Menü Sia aktivieren und ein paar Parameter übergeben:
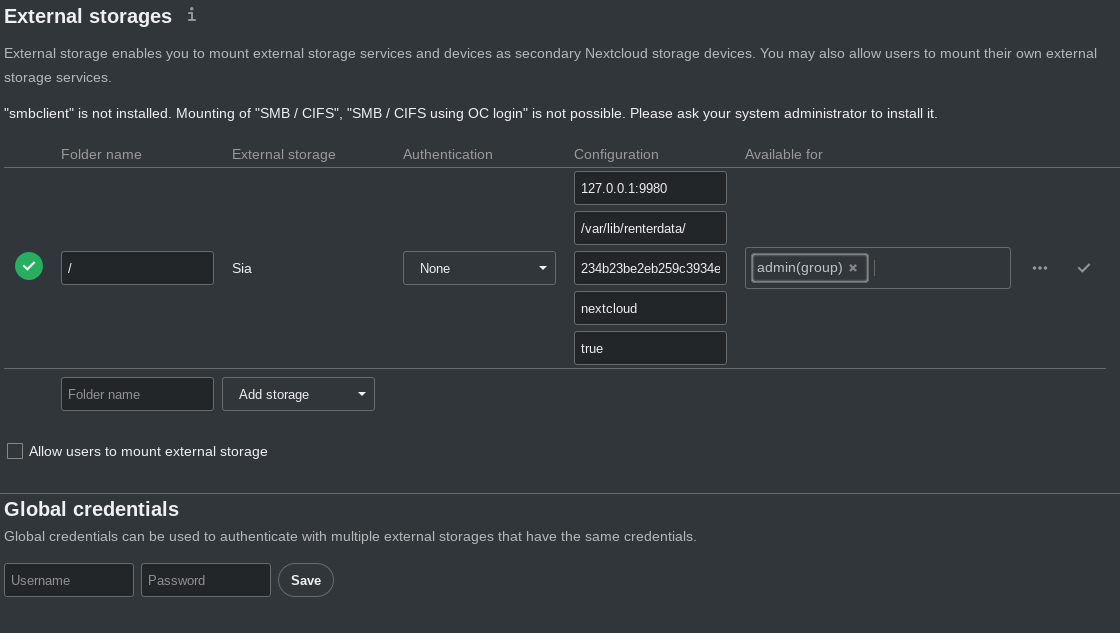
Der erste Parameter 127.0.0.1:9980 ist die Adresse des sia-Daemons siad. In dem Bild ist der default hinterlegt. Der zweite Parameter ist ein Verzeichnis auf dem Server, für welches der Webserver User (www-data) und der siad User Berechtigungen haben und dient als Cache Verzeichnis. Der dritte Parameter ist der API-Key. Diesen findet man nach der Installation von Siastream oder siad im Verzeichnis ~/.sia/apipassword. Nun kann man noch einen Prefix festlegen, wo die Daten im Sia-Storage abgelegt werden sollen, und ob Nextcloud für jeden Benutzer ein eigenes Unterverzeichnis bereitstellen soll, oder ob alle Daten für jeden sichtbar sind. Ist also “true” eingestellt, können die Benutzer die Dateien anderer Nutzer im Sia Storage nicht sehen. Wenn man zwei external Storages konfiguriert kann man aber einen so konfigurieren dass er als “shared” Storage für alle Nutzer funktioniert, der andere aber nur als Userverzeichnis. Es gibt keine Limits wieviele external Storages man anlegt.
Bei Fragen einfach kommentieren, Trinkgeld darf an:
SC: 1d9855ca88a07af2811fe6f277b062a6732cda68911ea34e43e8408bf4be376026a5b8c48218
XMR: 8C6KSu12hpZhBYGL7xC6QRF6u4z4obVzb1ZVgPKG7942dSGy3DG8ExMGNNcCw3wmJKGfmaSG2evhg7uiz545CWSuEazNqQ5
ETH: 0x08c5e7901BD68bD2058d4F09aB0a8e5a479622b6
#nextcloud #sia #siacoin #siastorage #siastream #cloud #cloudspace #dropbox #googledrive #decentralicedstorage
Anscheinend hat die Telekom mal wieder Ihren Login überarbeitet, sämtliche mir bekannte Zugänge funktionieren plötzlich nicht mehr. Gut das kann passieren, wenn der Anbieter den Login komplett umbaut.
Dämlich ist nur, dass das Formular als Sicherheitsfrage z.B. anbietet, den Namen des Vaters zu hinterlegen… Alle deren Väter einen Namen < 6 Zeichen haben, haben nun ein Problem, wie der folgende Screenshot beweist:
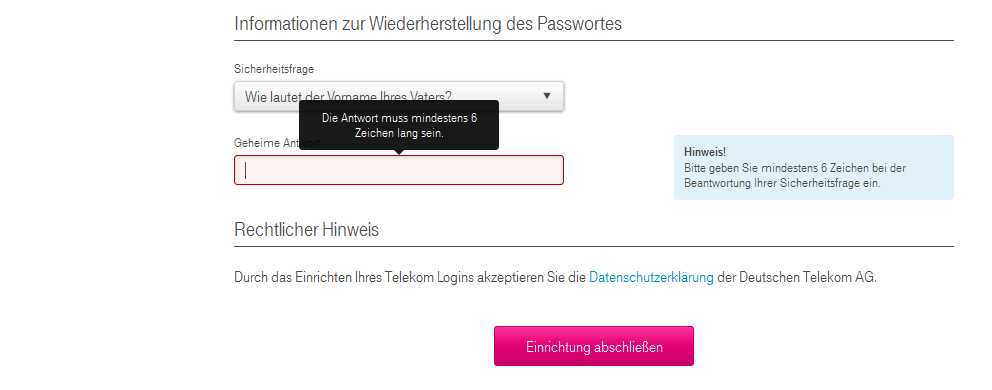
*FAIL* – Leider hat hier mal wieder jemand nicht zuende gedacht :/
Kürzlich habe ich etwas Hardware im RZ für unseren KVM VServer Cluster erweitert. Nun schafft unser Disk-Subsystem 1000MB/sek:
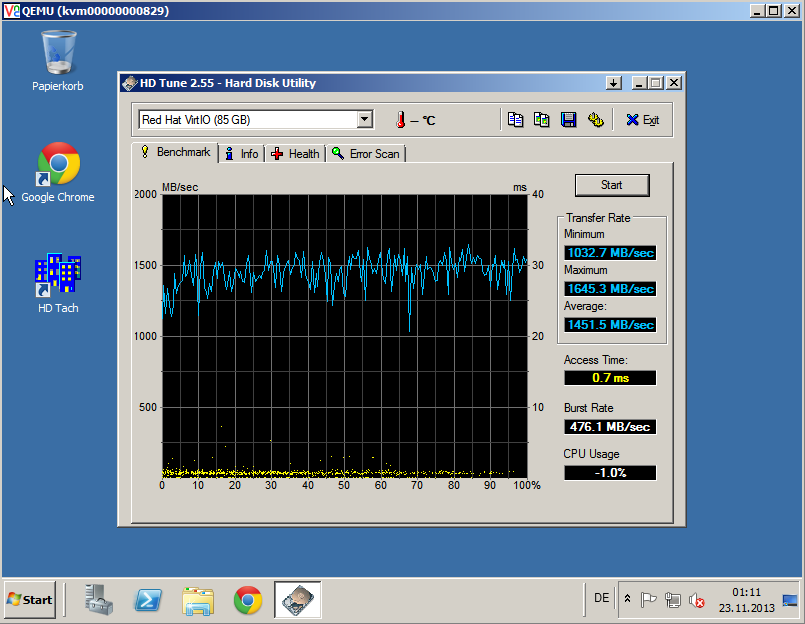
Benchmark mit 1MB Blocksize, unlimitiertem Disk-IO und 4 Cores, 4 GB RAM, normale KVM VServer haben ein Disk-IO Limit bei 50MB/s read, 30MB/s write.
Endlich weniger IO-Wait 🙂
Yippie!
Weil es doch öfter mal vorkommt, dass man in Webseiten mailto Links einbauen möchte und man meist
vermeiden will, dass die E-Mail Adressen von Spam-Crawlern erfasst werden gibt es hier mehrere Möglichkeiten dem entgegenzuwirken.
Weit verbreitet scheint das verschlüsseln der Mail-Adresse mittels Java-Script. Dies hat jedoch den Nachteil, dass der Browser Java-Script aktiviert haben muss. Gutes Webdesign sollte Java-Script nicht vorraussetzen. Man kann auch die E-Mail Adresse im mailto-Link durch dezimale HTML Entitäten darstellen, so dass diese im Browser ganz normal angezeigt werden und der mailto Link auch vom User benutzt werden kann, der E-Mail Harvester sieht jedoch nur HTML und kann daher die Adresse nicht parsen.
Den Encoder kann man hier testen.
Hier die zugehörige PHP-Funktion:
function spamschutz($email,$href = true) {
$returnemail=preg_replace( "/(.)/se", " '&#' . ord( '\\1' ) . ';' ", $email );
if ($href) {
return "$returnemail";
} else {
return $returnemail;
}
}
in der Dokumentation von mysql cluster wird immer darauf hingewiesen, dass man für ein redundantes Setup mindestens 3 Server benötigt: 2 Server für die NDB-Datenknoten und einen weiteren Server als separater Management-Server. Dies ist jedoch unschön, wenn man nur 2 physikalische Maschinen verwenden will/kann.
Mit etwas Konfigurationsarbeit und dem Linux VServer Patch (auf welchem auch die Vserver bei vlinux.biz laufen) lässt sich das Setup dennoch mit nur 2 Servern durchführen wobei auch ein Server komplett ausfallen kann, ohne dass der mysql cluster down ist oder crashed.
Man installiere ein Debian Lenny oder neuer, wähle entweder den bei Debian mitgelieferten VServer Kernel (linux-image-vserver-bigmem) oder baue seinen eigenen (z.B. 2.6.31.7-vs2.3.0.36.27 ) auf jeweils beiden Systemen.
Dann legt man auf den Servern vier virtuelle Server an:
vserver sql0[1-4] build –context 700[0-3] –hostname sql0[1-4]-n sql0[1-4] –interface sql0[1-4]=eth0:192.168.0.10-14 -m debootstrap — -d lenny
Danach wie gehabt mysql ndb herunterladen und installieren (z.B. mysql-cluster-gpl-7.0.9-linux-i686-glibc23) in /usr/local/ entpacken, und einen symlink auf /usr/local/mysql setzen.
Dann die Konfiguration (config.ini) wie folgt aufsetzen:
[NDBD DEFAULT]
NoOfReplicas: 2
DataDir: /var/lib/mysql-cluster
FileSystemPath: /var/lib/mysql-cluster
# Data Memory, Index Memory, and String Memory
DataMemory: 900M
IndexMemory: 300M
BackupMemory: 128M
MaxNoOfConcurrentOperations=100000
StringMemory=25
MaxNoOfTables=4096
MaxNoOfOrderedIndexes=2048
MaxNoOfUniqueHashIndexes=512
MaxNoOfAttributes=24576
TimeBetweenLocalCheckpoints=20
TimeBetweenGlobalCheckpoints=1000
TimeBetweenEpochs=100
MemReportFrequency=30
BackupReportFrequency=10
### Params for setting logging
LogLevelStartup=15
LogLevelShutdown=15
LogLevelCheckpoint=8
LogLevelNodeRestart=15
### Params for increasing Disk throughput
BackupMaxWriteSize=1M
BackupDataBufferSize=16M
BackupLogBufferSize=4M
[MGM DEFAULT]
PortNumber: 1186
DataDir: /var/lib/mysql-cluster
[NDB_MGMD]
Id:1
HostName: sql01
[NDB_MGMD]
Id:2
HostName: sql02
[NDB_MGMD]
Id:3
HostName: sql03
[NDB_MGMD]
Id:4
HostName: sql04
[NDBD]
Id:5
HostName: sql01
[NDBD]
Id:6
HostName: sql02
[NDBD]
Id:7
HostName: sql03
[NDBD]
Id:8
HostName: sql04
[API]
Id:9
HostName: sql01
[API]
Id:10
HostName: sql02
Nun die Management-Knoten auf allen vier VServern starten / initialisieren. Dazu in /usr/local/mysql
ndb_mgmd –initial -f config.ini
ausführen, anschliessend die 4 ndb Knoten starten (ndbd –initial)
Für die API Nodes natürlich noch mit ./scripts/mysql_install_db die mysql Datenbanken anlegen und anschliessend mit chmod mysql.mysql data -R die Rechte passend setzen.
Anschliessend sollte man mit ndb_mgm => show folgenden Output erhalten:
Cluster Configuration
———————
[ndbd(NDB)] 4 node(s)
id=5 @192.168.0.10 (mysql-5.1.39 ndb-7.0.9, Nodegroup: 0)
id=6 @192.168.0.12 (mysql-5.1.39 ndb-7.0.9, Nodegroup: 0, Master)
id=7 @192.168.0.11 (mysql-5.1.39 ndb-7.0.9, Nodegroup: 1)
id=8 @192.168.0.13 (mysql-5.1.39 ndb-7.0.9, Nodegroup: 1)
[ndb_mgmd(MGM)] 4 node(s)
id=1 @192.168.0.10 (mysql-5.1.39 ndb-7.0.9)
id=2 @192.168.0.12 (mysql-5.1.39 ndb-7.0.9)
id=3 @192.168.0.11 (mysql-5.1.39 ndb-7.0.9)
id=4 @192.168.0.13 (mysql-5.1.39 ndb-7.0.9)
[mysqld(API)] 2 node(s)
id=9 @192.168.0.10 (mysql-5.1.39 ndb-7.0.9)
id=10 @192.168.0.12 (mysql-5.1.39 ndb-7.0.9)
Nun sollte jeweils ein ndbd einer Nodegroup (0 und 1) auf einem physikalschen Server liegen, d.h. fällt ein Server aus, so sind immer noch mind. ein ndbd aus der jeweiligen Nodegroup verfügbar und der Cluster läuft weiterhin problemfrei.
Natürlich habe ich vorrausgesetzt, dass die Installation soweit fertig gestellt ist, d.h. mysql user angelegt, Datenverzeichnis angelegt (/var/lib/mysql-cluster – kann auch anders sein..) wurde etc. und in der my.cnf die Einträge für ndb gemacht wurden:
[mysql_cluster]
ndb-connectstring=sql01
[ndb_mgmd]
config-file=/usr/local/mysql/config.ini
php bietet aktuell ip2long() und long2ip() nur für IPv4 an, für IPv6 gibt es aktuell soweit ich weiss noch keine native Funktionen, deshalb hier meine zwei Funktionen um ip2long und long2ip auch für IPv6 zu verwenden – diese Funktionen benötigen die php gmp-lib, unter Debian: apt-get install php5-gmp:
$ipv6 = “2001:4860:a005::68”;
function ip2long6($ipv6) {
$ip_n = inet_pton($ipv6);
$bits = 15; // 16 x 8 bit = 128bit
while ($bits >= 0) {
$bin = sprintf(“%08b”,(ord($ip_n[$bits])));
$ipv6long = $bin.$ipv6long;
$bits–;
}
return gmp_strval(gmp_init($ipv6long,2),10);
}
function long2ip6($ipv6long) {
$bin = gmp_strval(gmp_init($ipv6long,10),2);
if (strlen($bin) < 128) {
$pad = 128 – strlen($bin);
for ($i = 1; $i <= $pad; $i++) {
$bin = “0”.$bin;
}
}
$bits = 0;
while ($bits <= 7) {
$bin_part = substr($bin,($bits*16),16);
$ipv6 .= dechex(bindec($bin_part)).”:”;
$bits++;
}
// compress
return inet_ntop(inet_pton(substr($ipv6,0,-1)));
}
print $ipv6long = ip2long6($ipv6).”\n”;
print $ipv6 = long2ip6($ipv6long).”\n”;
Ergebnis:
42541956150894553250710573749450571880
2001:4860:a005::68
Heute hatte ich mal etwas Zeit über, und konnte mich einem weiteren kleinen Problem welches aus dem Upgrade auf PHP5.3 resultiert widmen. Einige Funktionen sind bei PHP5.3 nicht mehr verfügbar, oder werden mit PHP6.0 nicht mehr unterstüzt. Auf der php Webseite gibt es eine Liste aller veralteten Funktionen.
In Typo3 4.3.0alpha3 ist davon zwar Einiges, wenn nicht sogar Alles behoben, im aktuellen Stable 4.2.8 gibt es jedoch eine Menge Probleme, wenn man auf PHP5.3 umstellt. Deshalb hier der von mir erstellte Patch für typo3 4.2.8 mit PHP5.3
typo3-4.2.8-php5.3-compat-patch
Falls jemand wider Erwarten einen Fehler findet und mir mitteilt, so werde ich den neuen Patch ebenfalls hier veröffentlichen.
Einen komplett gepatchten source gibt es hier zum download, da viele User nicht wissen wie man mit patch umgeht:
https://www.netz-guru.de/wp-content/uploads/2009/07/typo3_src-4.2.8-compat-patched-php5.3.tgz
Bei vielen Shop-Systemen wird XT-Commerce eingesetzt, da es vielseitig und flexibel ist um den meisten Anforderungen gerecht zu werden. Will man XTC jedoch in einer Cluster-Umgebung einsetzen, und hat einen Mailserver-Cluster zur Verfügung, gibt es ein Problem sobald XTC versucht, einen Connect zu einem Mailserver aufzubauen, der gerade nicht erreichbar ist. Obwohl weitere Server des Mailserver-Clusters verfügbar sind, gibt XTC nach einmaligem Versuch auf.
Hier ein kleiner Fix für XTC, damit zu einem Hostname alle verfügbaren IP-Adressen zum versenden von Mail durchprobiert werden:
In Zeile 106 in
/includes/classes/class.smtp.php
einfügen:
// retry connections $hosts = gethostbynamel($host); while ((empty($this->smtp_conn)) && (count($hosts) > 0)) { $this->smtp_conn = fsockopen(array_pop($hosts), #server $port, # the port to use $errno, # error number if any $errstr, # error message if any $tval); # give up after ? secs }
Damit versucht nun XTC mehrmals Mails zuzustellen, wenn der erstmalige Connect zu einem MTA fehlschlägt.