Es war einmal ein Mailserver…
Wenn man Administrator eines produktiv genutzten Mailservers ist, macht man sich schon ab und zu mal Gedanken, wie man die Probleme, welche beim Betrieb des Servers auftreten oder auftreten könnten, mit möglichst wenig Aufwand – jetzt im Sinne von möglichst wenig Aufwand in der Zukunft – lösen kann. Ich betreibe einen kostenlosen E-Mail Dienst mit derzeit ca. 12.000 Usern. Seit 1998 hat sich das Setup des Mailservers eigentlich kaum geändert. Damals war sendmail noch das Nonplusultra, man war stolz dass SMTP-Auth und diverse Workarounds wie POP-Before-SMTP etc funktionierten, und im Allgemeinen gab es auch weniger SPAM. Zu dieser Zeit hatte quickemail.de ca. 500 User und die Welt der Flat-File Konfiguration war noch in Ordnung.
Irgendwann reicht das jedoch nicht mehr aus – Flat-Files werden schnell unübersichtlich und es musste eine Lösung her, um zumindest die E-Mail Accounts und User zu verwalten. Eine mySQL Datenbank war schnell aufgesetzt und mit ein paar Scripts und Cronjobs wuchs die Userbase dann immer weiter an. Da gingen dann aber auch die Probleme los.
SPAM von Botnets == DDOS?
Wenn man mehrere tausend User auf einer physikalischen Maschine hat, bringt das diverse Probleme mit sich. Zum einen braucht man ständig größere Festplatten, zum anderen natürlich auch mehr CPU und RAM. Das lässt sich eigentlich auf normaler Hardware noch relativ einfach erweitern. Problematisch wird das ganze dann, wenn man distributed SPAM von diversen Botnets abbekommt. Nicht nur der Mailserver an sich ist hier dann überfordert – bei jedem Connect wird ein nslookup durchgeführt, was sich auch wieder mit erhöhter Last auf den Nameservern auswirkt. Irgendwann ist dann jedoch Schluss – bei 200 gleichzeitigen Connects und einer Load von >100 kann es schon mal ein paar Minuten dauern, bis man diverse Services gestoppt hat um zumindest die Maschine wieder administrieren zu können.
SPOFs am laufenden Band
Eine einzelne Maschine zu verwenden ist natürlich auch nicht gerade von Vorteil. Fällt die Hardware aus, oder sind die Platten voll, steht die Maschine und nichts geht mehr. Klar kann man solche Ausfälle durch gutes Monitoring minimieren, spätestens jedoch beim nächsten Upgrade steht der Dienst erst mal wieder.
Wie man diese Probleme in den Griff bekommt?
Nun, wenn man nicht gerade im Lotto gewonnen hat, braucht man hier eine günstige Lösung die dennoch gut skaliert und fehlertolerant ist, also die Mails an sich redundant speichert, sowie mehrere Server zur Verfügung stellt um bei einem ausgefallenen System dennoch den Dienst aufrecht erhalten zu können. Das gestaltet sich jedoch gar nicht so einfach. Alleine dafür zu sorgen, dass die Daten auf allen Maschinen synchron sind, ist eine Herausforderung.
Es gibt diverse Lösungen mit NAS oder DRBD, proprietäre Lösungen von diversen Herstellern, Backup-Mailserver, etc – aber eine wirkliche günstige Alternative die mit normaler x86er Hardware auskommt, und bei der man nicht Tausende Euro Lizenzgebühren zahlen muss, hatte ich bisher noch nicht gefunden.
Deshalb habe ich mich mal eine Woche intensiv damit beschäftigt, das Mailproblem, zumindest für mich, ein für alle mal zu Lösen.
Daten redundant speichern…
kann man zum Beispiel mit mysql-ndb – Das war auch mein erster Versuch. Da man seit mySQL 5.1.6 bzw. der 6.2er NDB-Engine endlich Tables auch ondisk speichern kann, dachte ich das sei einen Versuch wert. Allerdings gibt es bei mySQL immer noch das Problem, dass die Indizes in-memory sein müssen. Bei einer Mailbase von sagen wir mal ca. 40GB kommt man so locker auf einen RAM-Bedarf von 8GB und mehr.
Dann gibt es noch die Möglichkeit dies einfach mit Master-Slave Replication zu lösen, hier ist jedoch das Problem, dass sobald der Master-Server ausgefallen ist, die User keine Daten mehr schreiben können und man nur noch Read-Only Access hat. Deshalb sind auch Lösungen wie PG-Pool oder Slony nicht wirklich praktikabel. Aber es gibt ja noch PGCluster. PG-Cluster ist im Vergleich zu mySQL-NDB wesentlich besser geeignet, um Daten redundant in einer Datenbank zu speichern. Hier müssen die Indizies nicht in-memory sein. Das derzeitige Release pgcluster1.9-rc5 basiert auf postgres 8.3 und funktioniert – sofern richtig konfiguriert – einwandfrei. Schade ist jedoch, dass auf der offiziellen Webseite von PG-Cluster immer noch die Version 1.3 als aktuell bezeichnet wird und das letzte Update der Seite irgendwann in 2005 war. Deshalb habe ich während der Evaluierungsphase erst PG-Cluster 1.3, dann den Fork cybercluster, und dann erst PG-Cluster 1.9 getestet. Mit PG-Cluster hat man zumindest schon mal das Problem ausgemerzt, dass man sich nicht mehr darum kümmern muss, was mit den Daten passiert. Die Master-Master oder auch Active-Active Replikation von PG-Cluster gewährleistet synchrone Daten über alle Cluster-Nodes hinweg.
Redundante Daten – und was machen wir nun damit?
Nach einiger Zeit googeln bin ich dann auf den dbmail gestossen – ein User aus dem IRC-Channel #linux.de hatte mich darauf hingewiesen, dass es soetwas bereits gibt. Bei dbmail werden alle E-Mails, Accounts, Forward etc. in der Datenbank gespeichert. In Verbindung mit PG-Cluster ergibt sich dann hier eben die Möglichkeit, Mailserver-Nodes zu betreiben die synchron sind. Die Last lässt sich dann via DNS-Roundrobin über die Mailserver und bei der Datenbank mit dem PG-Loadbalancer verteilen. Mein aktuelles Setup sieht wie folgt aus:
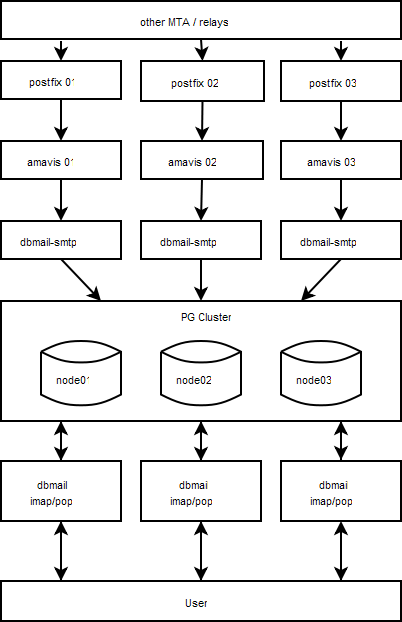
Mit diesem Setup ist man dann in der Lage, solange zumindest ein Node online ist, die Mail-Services aufrecht zu erhalten. dbmail liefert ein Script mailbox2dbmail mit – damit lassen sich Mailboxen im mbox, maildir und mhdir Format leicht in dbmail einpflegen. Wie man so ein Setup bewerkstelligt, möchte ich hier nun kundtun. Ich selbst habe für mein aktuelles Setup ca. eine Woche gebraucht – das liegt aber auch daran, weil ich alles Mögliche getestet habe um herauszufinden, was am Besten funktioniert. Bei dbmail musste ich selbst einige Zeilen im Source-Code ändern. Auch Cyrus SASL muss man patchen, aber am Ende ist es das Alles wert.
Howto begin?
Als aller erstes benötigen wir mind. 2 Server. Wer möchte kann das auch zuerst innerhalb eines VServers oder VMware Session testen – ich rate dringend dazu, um sich mit der Sache etwas vertraut zu machen.
Die Server werden frisch mit Debian Etch installiert. Damit hier pgcluster allerdings kompiliert, müssen einige Pakete nachinstalliert werden – und nach dem ./configure muss man noch ein Makefile anpasssen. Benötigt wird build-essential libreadline5 libreadline5-dev asciidox flex bison libssl-dev rsync ssh. Sollte hier noch etwas fehlen, werde ich es zu gegebener Zeit ergänzen. Wichtig ist, dass das System eine utf8-Locale installiert hat und diese auch verwendet wird – sonst gibt es später Probleme mit PostgreSQL.
wget http://pgfoundry.org/frs/download.php/1705/pgcluster-1.9.0rc5.tar.gz tar -xvzf pgcluster-1.9.0rc5.tar.gz cd pgcluster-1.9.0rc5 ./configure make make install
Postgres wird dann in /usr/local/pgsql installiert. Wer es woanders haben möchte, gibt einen Prefix beim configure mit an.
User anlegen, Rechte setzen:
cd /usr/local useradd -d /usr/local/pgsql postgres groupadd postgres chown postgres.postgres pgsql -R
Hat man dies auf allen Nodes erledigt, wird mit initdb die Datenbank initialisiert:
su postgres cd /usr/local/pgsql ./bin/initdb --locale=de_DE.utf8 data
Im Verzeichnis data legen wir dann auch entsprechend die Konfiguration für den Cluster an. Wichtig ist hierbei dass die Konfiguration bei allen Nodes identisch ist. Zuerst muss man die Datei pg_hba.conf im data Verzeichnis bearbeiten. Hier wird festgelegt, welcher Rechner sich zu der Datenbank verbinden darf. Das Ganze ist IP-basierend. Man sollte in jedem Fall für jeden Host einen eintrag in /etc/hosts machen, um DNS-Problemen innerhalb des Clusters aus dem Weg zu gehen – ich gehe hier bei diesem Howto mal davon aus, dass zuerst das ganze in einer Testumgebung installiert wird:
In pg_hba.conf unter der Zeile:
# IPv4 local connections:
muss für jeden Host des Clusters ein Eintrag gemacht sein:
host all all 192.168.0.10/32 trust # node01 host all all 192.168.0.20/32 trust # node02
Dies stellt sicher, dass die Nodes des Clusters gegenseitigen Zugriff auf sich selbst haben. Wichtig: man darf es nicht versäumen auch dem lokalen node Connections von sich selbst zu erlauben – daher ist auch bei node01 die IP für den node01 freizugeben.
Nun müssen wir die Datei cluster.conf im data Verzeichnis anlegen. Hier wird festgelegt, wohin repliziert werden soll:
<Replicate_Server_Info>
<Host_Name> node01 </Host_Name>
<Port> 5810 </Port>
<Recovery_Port> 5811 </Recovery_Port>
</Replicate_Server_Info>
<Replicate_Server_Info>
<Host_Name> node02 </Host_Name>
<Port> 5810 </Port>
<Recovery_Port> 5811 </Recovery_Port>
</Replicate_Server_Info>
</Replicate_Server_Info>
<Host_Name> node01 | node02 </Host_Name>
# Der Host_Name muss dem jeweiligen Node angepasst werden!
#
<Recovery_Port> 5611 </Recovery_Port>
<Rsync_Path> /usr/bin/rsync </Rsync_Path>
<Rsync_Option> ssh </Rsync_Option>
<Rsync_Compress> yes </Rsync_Compress>
<When_Stand_Alone> read_write </When_Stand_Alone>
<Pg_Dump_Path> /usr/local/pgsql/bin/pg_dump</Pg_Dump_Path>
<Replication_Timeout> 1min</Replication_Timeout>
<LifeCheck_Timeout>3s</LifeCheck_Timeout>
<LifeCheck_Interval>15s</LifeCheck_Interval>
Nachdem die cluster.conf angelegt wurde, fehlt noch die pgreplicate.conf – hier wird festgelegt, von welchen Nodes gelauscht werden soll um die Queries zu replizieren:
<Cluster_Server_Info>
<Host_Name> node01 </Host_Name>
<Port> 5432 </Port>
<Recovery_Port> 5611 </Recovery_Port>
</Cluster_Server_Info>
<Cluster_Server_Info>
<Host_Name> node02 </Host_Name>
<Port> 5432 </Port>
<Recovery_Port> 5611 </Recovery_Port>
</Cluster_Server_Info>
<Host_Name> node01 | node02 </Host_Name>
# Der Host_Name muss dem jeweiligen Node angepasst werden!
#
<Replication_Port> 5810 </Replication_Port>
<Recovery_Port> 5811 </Recovery_Port>
<Response_Mode> normal </Response_Mode>
<Use_Replication_Log> yes </Use_Replication_Log>
<RLOG_Port> 8301 </RLOG_Port>
<Replication_Timeout> 1min </Replication_Timeout>
<LifeCheck_Timeout> 3s </LifeCheck_Timeout>
<LifeCheck_Interval> 15s </LifeCheck_Interval>
Soweit so gut, PG-Cluster sollte jetzt lauffähig sein und Queries replizieren. Starten müssen wir das Ganze auf beiden Nodes noch:
su postgres cd /usr/local/pgsql ./bin/pg_ctl -D data start ./bin/pgreplicate -D data
Man kann jetzt das ganze einmal testen indem man einfach eine Datenbank erzeugt, eine Tabelle anlegt, und von beiden Nodes Inserts durchführt:
./bin/createdb test ./bin/psql testcreate table test ( test varchar(255));# Dann jeweils auf beiden Nodes abwechselnd # insert into test (test) values (test1); insert into test (test) values (test2); select * from test;Man kann jetzt beobachten, wie die Queries repliziert werden.
dbmail Setup
Auch hier müssen wir zuerst dbmail holen, entpacken und installieren:
cd /usr/src wget http://www.dbmail.org/download/2.2/dbmail-2.2.11-rc3.tar.gz tar -xvzf dbmail-2.2.11-rc3.tar.get cd dbmail-2.2.11-rc3 ./configure --with-pgsql=/usr/local/pgsql Unter Debian Etch man/Makefile editieren, Zeile 547: von: asciidoc -b docbook -d manpage $< zu: asciidoc --unsafe -b docbook -d manpage $< make make installdbmail ist jetzt in /usr/local/sbin installiert. Die Konfiguration dbmail.conf kann man nach /etc/ kopieren und anpassen. Wer pglb (Loadbalancer) verwenden will, muss vor dem kompilieren in modules/dbpgsql.c nach Zeile 110 Folgendes einfügen:
g_string_append_printf(cs, " sslmode='disable'");und der eigentliche MTA?
nun fehlt noch postfix. Postfix wird mit apt-get install postfix postfix-pgsql installiert. Wenn man sasl verwenden möchte, sei darauf hingewiesen, dass man hier ein gepatchtes sasl braucht, welches gecryptete Passwörter in der DB zulässt. Meine main.cf für Postfix sieht dann so aus:
smtpd_banner = $myhostname ESMTP $mail_name (Debian/GNU) biff = no append_dot_mydomain = no smtpd_tls_cert_file=/etc/ssl/certs/ssl-cert-snakeoil.pem smtpd_tls_key_file=/etc/ssl/private/ssl-cert-snakeoil.key smtpd_tls_session_cache_database = btree:${queue_directory}/smtpd_scache smtp_tls_session_cache_database = btree:${queue_directory}/smtp_scache myhostname = node01 alias_maps = hash:/etc/aliases alias_database = hash:/etc/aliases myorigin = /etc/mailname mydestination = $myhostname, mysql:/etc/postfix/sql-mydestination.cf mynetworks = 127.0.0.0/8 mailbox_command = procmail mailbox_size_limit = 0 recipient_delimiter = + local_recipient_maps = pgsql:/etc/postfix/dbmail_rcpt.cf, pgsql:/etc/postfix/dbmail_rcpt_alias.cf local_transport = dbmail-smtp: broken_sasl_auth_clients = yes smtpd_sasl_auth_enable = yes smtpd_sasl_security_options = noanonymous smtpd_recipient_restrictions = permit_mynetworks, reject_invalid_hostname, reject_non_fqdn_sender, reject_non_fqdn_recipient, reject_unknown_recipient_domain, reject_unauth_pipelining, reject_unknown_sender_domain, permit_sasl_authenticated, reject_unauth_destination smtpd_sender_restrictions = permit_mynetworks, reject_authenticated_sender_login_mismatch, permit_sasl_authenticated, reject_sender_login_mismatch, reject_unknown_sender_domain, reject_unauth_destination, reject_unknown_recipient_domain check_sender_access = hash:/etc/postfix/sender_access smtpd_sender_login_maps = pgsql:/etc/postfix/dbmail_sender_login.cf, pgsql:/etc/postfix/dbmail_sender_login_alias.cf content_filter = smtp-amavis:[127.0.0.1]:10024Dann hier noch die Files welche für sasl benötigt werden:
cat dbmail_rcpt.cf user = dbmail password = xxxxxxxxxxx dbname = dbmail hosts = node01 query = SELECT userid FROM dbmail_users WHERE userid='%s' cat dbmail_rcpt_alias.cf user = dbmail password = xxxxxxxxxx dbname = dbmail hosts = node01 query = SELECT alias FROM dbmail_aliases WHERE alias='%s' cat dbmail_sender_login.cf user = dbmail password = xxxxxxxxxx dbname = dbmail hosts = node01 query = SELECT userid FROM dbmail_users WHERE userid='%s' cat dbmail_sender_login_alias.cf # SMTP AUTH - check if the alias exists user = dbmail password = xxxxxxxxxx dbname = dbmail hosts = node01 query = SELECT userid FROM dbmail_users JOIN dbmail_aliases ON ( CAST (dbmail_aliases.deliver_to as bigint)=cast(dbmail_users.user_idnr as bigint)) WHERE dbmail_aliases.alias='%s'; cat sql-recipients.cf user = dbmail password = xxxxxxxxxxxxx hosts = node01 dbname = dbmail query = SELECT alias FROM dbmail_aliases WHERE alias='%s' UNION SELECT userid FROM dbmail_users WHERE userid='%s';Ich selbst habe meine relay-Domains noch in der mySQL Datenbank stehen, hier kann aber auch einfach nur das Hash-File verwendet werden. Jetzt steht die Postfix Konfiguration auch soweit. Wir müssen jetzt noch das DB-Layout in der Datenbank anlegen:
su postgres cd /usr/local/pgsql ./bin/createdb dbmail ./bin/createuser dbmail ./bin/psql -U dbmail dbmail </usr/src/dbmail-2.2.11-rc3/sql/postgresql/create_tables.pgsqlNun kann man postfix starten/restarten. Die pop3 und imap services startet man in /usr/local/sbin mit ./dbmail-imapd sowie ./dbmail-pop3d – Nützlich ist auch dbmail-users und dbmail-util.
Die amavis Konfiguration sowie das Anlegen und Verwalten von Usern möchte ich hier nicht weiter behandeln, da hier wohl jeder Admin seine eigenen Preferenzen hat. Dennoch hoffe ich hier etwas Wissen in PG-Cluster und dbmail vermittelt zu haben und wünsche viel Spass mit dem neuen Mailsetup. Die bisherigen Probleme sollten damit alle passé sein.
Hast Du jemals einen Node offline und wieder online genommen?
Mit der option -U macht er dann ja einen Dump aber wie zuverlässig funktioniert dass ganze in oder nach einem totalausfall?
Ich bin mittlerweile zu einem Setup mit GlusterFS gewechselt, siehe die anderen Posts. Die Problematik bei postgreSQL ist einfach, dass hier das Clustering nicht wirklich ausgereift ist – vielleicht hat sich dies aber ziwschenzeitlich auch schon wieder geändert, aber ich habe dies dann nicht weiter verfolgt, da die Lösung mit GlusterFS reibungslos funktioniert.
Gut zugegeben, bei maildir etc. gibts das Problem nicht, aber bei NFS gibts halt wieder SPOF.
Das mbox-Format ist für konkurierende Zugriffe einfach ungeeignet. maildir, maildir++ und letztlich imapdir haben damit keine Probleme, auch nicht mit NFS-Shares.
Tux2000
Schade, daß nicht nicht klar herausgearbeitet wird, warum genau die Mails in einer Datenbank und nicht auf einem Dateisystem gespeichert werden sollen. Dateisysteme skalieren für Ihren ureigenen Zweck, nämlich Dateien unterschiedlicher Größe zu speichern, nach meinen Erfahrungen schneller als Datenbanken, und um hier Redundanz herzustellen, gäbe es viele Lösungsansätze. Spontan fallen mir hier Raid-Systeme, die man mittels NFS prima an beliebig viele Mailserver andocken kann oder ohne SPOF gleich verteilte Dateisysteme ein.
Die Konfiguration der Konten/Forwarder usw. läßt sich inzwischen heute bei vielen MTAs mit beliebigen Backends verwalten: Für qmail gibt es u.a. vpopmail, welches LDAP, Postgres, Mysql, Oracle, Sybase, CDB dafür benutzen kann. Virenscan mit ClamAV und Spamassassin-Check lassen sich auf andere Maschinen oder auch Cluster auslagern, so daß man nicht nur Redundanz gewinnt, sondern auch Rechenzeit genau am Flaschenhals nach Bedarf positionieren kann.
Verteilte Dateisysteme gibt es zwar, jedoch habe ich auch hier bisher nur wenig ausgereifte Open-Source Software dazu gefunden. Ich weiss nicht inwieweit z.B. Unix-Mbox damit klar kommt, wenn zwei MTAs gleichzeitig versuchen in ein File zu schreiben. Oder ein IMAP-User gerade sein Maildir umbenennt während ein MTA gerade eine Mail ausliefern will – diese Probleme hat man mit einer Datenbank nicht. Dass die Datenbank an sich nicht schneller ist, als einfach nur Files/Mails auf die Platte zu schreiben, das mag wohl sein. Allerdings ist jetzt E-Mail nicht gerade performancekritisch. Wo man den Unterschied dennoch bemerkt ist eben wenn man sehr viele E-Mails in einem Maildir hat – da wird die Lösung mit DB-Mail auf jeden fall schneller sein, denn ab ein paar tausend Files in einem Directory dauert das Listen der Files schon mal eine halbe Ewigkeit, während das durchsuchen des Index auf der Datenbank dazu im Verhältnis wesentlich schneller ist. Auch bei Lösungen wie DRBD oder NFS Exports über mehrere RZs verteilt is das Delay da schon sehr kritisch. Soetwas lässt sich mit einer verteilten DB meiner Meinung nach eben viel leichter realisieren.
Ein Backup sollte nicht darauf basieren, dass man die Daten nun 3-fach redundant gespeichert hat, schreibt eine DB Muell in die anderen Nodes ist auch fuer diese schnell Ende.
Desweiteren ist es vielleicht ganz schoen 3 all-in-one Maschinen zu haben, es sollten also 2 ausfallen duerfen und es funktioniert noch, allerdings skaliert das nur begrenzt, denn reichen diese nicht, muss man mit einer 4. oder 5. all-in-one Maschine ausbauen, meistens ist jedoch nur ein bestimmter Task der Flaschenhals, erweitert man diesen gezielt nuetzt er auch allen anderen Nodes (z. B. eine weitere dediziert Kiste mit amavis oder so, jenachdem was am meisten zieht).
ntx
Sicherlich kann man bei diesem Setup amavis oder auch den Postfix auf dedizierte Maschinen auslagern, wenn man hier mehr Performance braucht. Ein tägliches Backup der DB hatte ich als selbstverständlich angesehen.